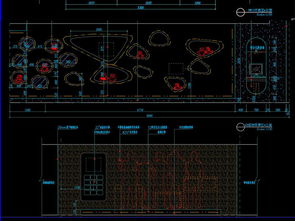
在當今快速發展的通信行業,移動公司的營業廳、辦公樓、數據中心等各類場所的裝修與建設,離不開專業、精確的設計圖紙。一套完整的移動公司工裝施工CAD圖紙及平面設計效果圖,不僅是施工的藍圖,更是確保工程效率、成本控制與最終視覺效果的關鍵。本文將深入探討這類圖紙的構成、價值以及如何有效獲取與利用。
一、 移動公司工裝設計圖紙的核心構成
一套標準的移動公司工裝設計圖紙包通常包含以下幾個核心部分,它們共同構成了從概念到落地的完整設計鏈條:
- 施工圖(CAD圖紙):這是工程的技術核心,通常以.dwg或.dxf格式保存。它包含了精確的平面布置圖、天花布置圖、地面鋪裝圖、電氣點位圖、強弱電布線圖、立面圖、剖面圖及節點大樣圖等。CAD圖紙以其矢量特性,能清晰展示所有尺寸、材料、工藝和施工細節,是施工人員、項目經理和監理方必須嚴格遵循的依據。
- 效果圖:效果圖(如用戶提到的“圖片2.99mb”這類文件)是設計的視覺呈現,通常為JPG或PNG格式。它通過3D渲染技術,將CAD圖紙中的空間、材質、燈光和色彩生動地模擬出來,讓非專業人士(如決策層、客戶)能夠直觀預覽裝修完成后的實景效果,便于方案的溝通與定稿。
- 平面設計圖:此部分更側重于視覺識別與品牌傳達。包括營業廳的標識系統(Logo墻、導向牌)、宣傳展板、文化墻、柜臺裝飾等平面元素的布局與設計。它確保了移動公司的品牌形象在物理空間中得到統一、專業的展示。
二、 “工裝施工CAD圖紙大全”的價值與應用
所謂“工裝施工CAD圖紙大全”,通常指經過整理歸納的、涵蓋多種場景(如標準營業廳、VIP接待室、機房、辦公區、休息區等)的成套CAD圖紙資源庫。其價值體現在:
- 提高效率:設計師或施工方可以直接參考或調用其中的標準化模塊(如柜臺、展示架、弱電機柜基礎),大幅縮短設計周期。
- 保證質量:成熟的圖紙經過了實際項目的檢驗,能有效避免常見的設計錯誤和施工隱患。
- 統一標準:有助于移動公司在全國或全區范圍內建立統一的店面形象和施工標準,強化品牌認知。
- 成本優化:標準化的設計有助于材料的集中采購和施工流程的規范化,從而控制成本。
三、 如何有效獲取與利用相關圖紙資源
對于需要下載或參考此類圖紙的用戶,建議通過以下正規、高效的途徑:
- 內部資源系統:大型移動公司或其合作的裝飾設計公司通常建有內部的項目圖紙數據庫或知識管理系統,這是獲取最準確、最權威圖紙的首選渠道。
- 專業設計網站與平臺:國內外的專業設計資源網站(如知末、3D溜溜網、ArchDaily等)以及專業的CAD圖紙分享社區,提供了海量的商業空間案例和圖紙素材。用戶可以根據“移動營業廳”、“通訊空間”等關鍵詞進行搜索篩選。注意甄別資源的準確性和時效性。
- 與專業設計機構合作:對于重要的新建或改造項目,最可靠的方式是委托具有通信行業工裝經驗的專業設計公司。他們不僅能提供完全定制化的全套圖紙(CAD施工圖、效果圖、平面設計),還能提供從報建到驗收的全流程服務。
- 注意事項:
- 版權意識:下載和使用任何圖紙資源時,務必尊重知識產權,明確其使用許可范圍,避免用于商業侵權。
- 圖紙驗證:即使獲得參考圖紙,也需結合現場實際情況(如房屋結構、管線排布、消防規范)進行復核和修改,切勿直接套用。
- 文件管理:類似“2.99mb”的效果圖文件,應妥善歸檔,并與對應的CAD圖紙、設計說明等文件關聯存放,便于項目團隊協作。
###
移動公司工裝項目的成功,始于一套詳盡、專業且兼具實用性與美觀性的設計圖紙。無論是追求高效參考的“圖紙大全”,還是用于最終呈現的“效果圖”與指導施工的“CAD圖紙”,都是項目不可或缺的組成部分。通過合理的渠道獲取并科學地利用這些資源,將能顯著提升項目品質,助力移動公司在激烈的市場競爭中,通過卓越的實體空間體驗贏得客戶。